
A Brief Introduction to Alibaba's Canal
In the previous article, I introduced the deployment of our Elasticsearch cluster, which is used for a product retrieval system. In order to synchronize the data from MySQL database to our ES cluster in near real time, we investigated many middle wares, and finally chose the Canal as our solution. Canal is a data synchronization middle ware, which is one of Alibaba’s open source projects. The way it works is that it disguises itself as the slave database and ingests data from a real master database. By parsing the binary logs, it re-plays the events happened in the master database, and pushes the events in the form of messages to its downstream.
In this article, I will firstly introduce the background, then the general structure of Canal, and in the end I will talk about its high availability (HA) design. This article is entirely technical, anything related to commercial information has been excluded.
The Background
In the early days, Alibaba group has the demands of synchronizing data over geographical and temporal distances, due to their databases were deployed in Hangzhou and United States. Since 2010, Alibaba attempted to parse the binary logs of databases to synchronize data incrementally. This led to the birth of project Canal, and opened a new era.
- Language: Developed entirely in Java.
- Positioning: Currently supports MySQL, providing incremental data subscription and consumption.
How Canal Works
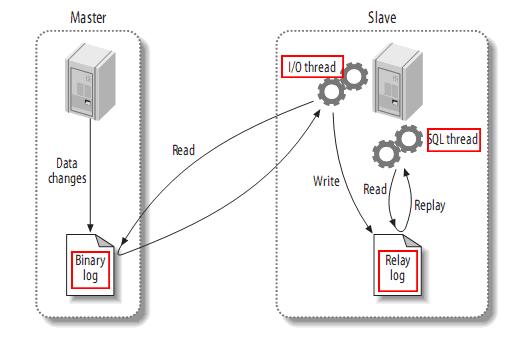
The Data Synchronizing Process of MySQL
The process takes three steps:
- The master records the changes of database to its Binary Log, these changes are called “binary log events”.
- The slave database copies the binary log events to its Relay Log.
- The slave re-plays the events in its Relay Log, and adds these changes to its own data.
The Binlog
The binlog in MySQL:
- The binlog of MySQL is stored in multiple files. Thus we need binlog filename and binlog position to locate one Log Event.
- Based on the way it was generated, the formats of MySQL’s binlog are classified as three types, they are: statement-based, row-based and mixed.
Currently, Canal supports all binlog formats when performing incremental subscription. But when it comes to data synchronization, only row-based format is appropriate, because the statement-based format doesn’t contain any data at all.
How Canal Works
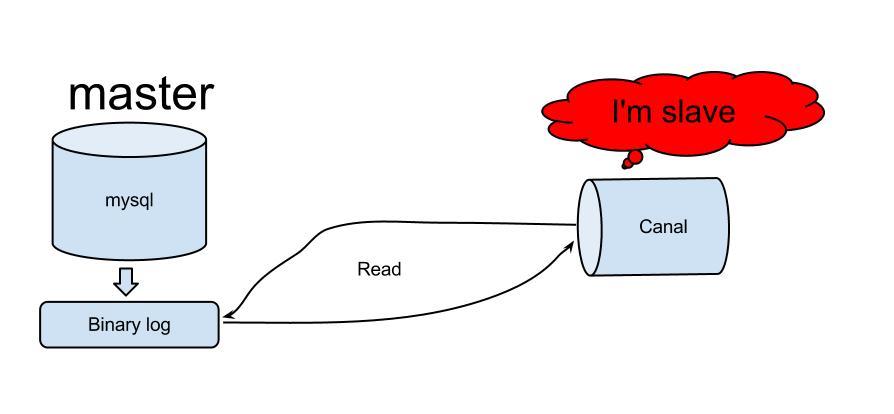
The data synchronization of Canal takes three steps:
- Canal disguises itself as the slave database and communicates with a real master database via dump protocol.
- Once the master receives the dump requests, it pushes binlogs to the slave, which is actually a Canal server of course.
- The Canal server parses the binlogs, replays the events happened in the master database, and pushes the events in the form of messages to its downstream.
The Architecture
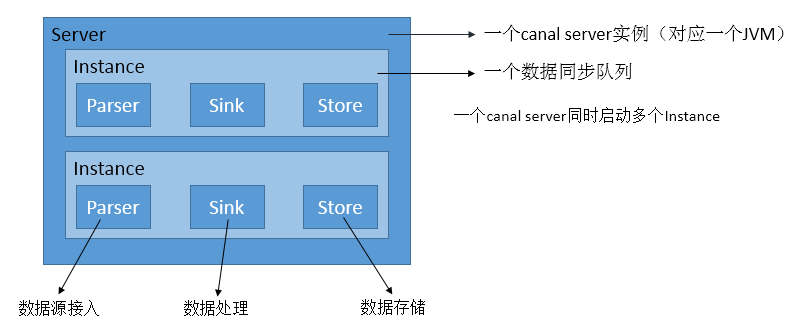
As shown in this figure:
- A Server is a running instance of Canal, which corresponds to one JVM.
- An Instance in this figure corresponds to a data processing (synchronization) queue, and one Canal server could contain 1 to n Instances.
- In every Instance, there are three important components, they are: eventParser, eventSink and eventStore.
- The eventParser: disguises itself as the slave, parses binlog and digests data from a real master database.
- The eventSink: links the Parser and Store, performs the data processing, filtering, dispatching, etc.
- The eventStore: stores the data.
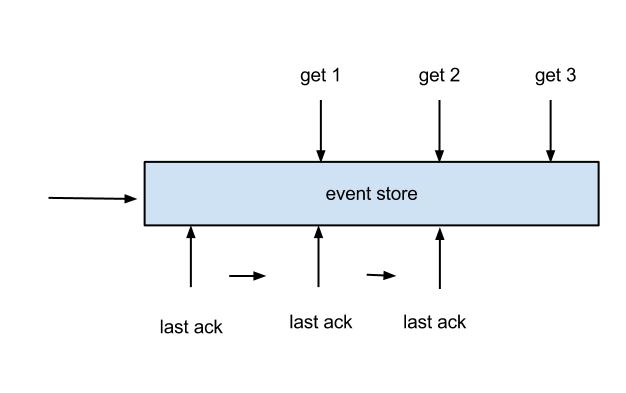
The eventStore Component
The design of a ring buffer:
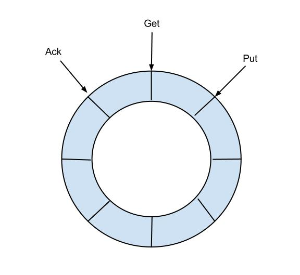
The eventStore is a circular message queue in the memory. It defines three cursor:
- Put: The last position where the message from Sink module was written.
- Get: The last position where the message was subscribed.
- Ack: The last position where the message was successfully consumed.
Canal allows to perform Get/Ack operations asynchronously. For example, you can invoke Get several times continuously, then invokes Ack or Rollback in sequence. This is called streaming API in Canal.
The HA Mechanism
The High Availability (HA) mechanism of Canal relies on Zookeeper. It contains two parts:
- The HA of Canal server: The instances are distinguished by their destination names, if an instance in canal-server01 has the same destination name with the instance in canal-server02, only one of them is allowed to run, in the meanwhile, the other one is in standby state.
- The HA of Canal client: One Instance in the Canal Server only allows to be consumed by one Canal client simultaneously.
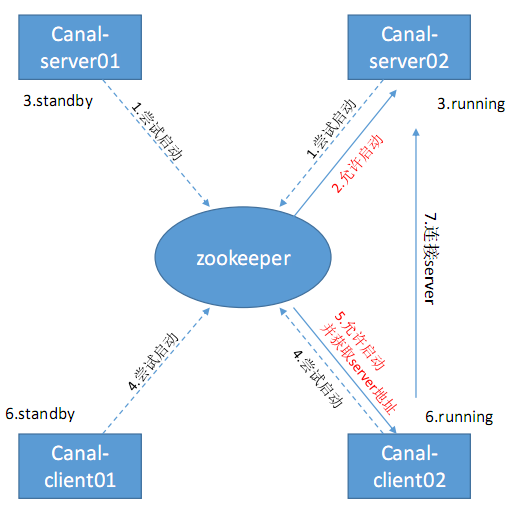
As shown in this figure, the procedure of starting up is:
- Canal-server01 and Canal-server02 will preemptively create the Ephemeral Node in Zookeeper when they are attempting to start their own Instances with the same destination name.
- The one who successfully created the Ephemeral Node, will start running its instance; The one who didn’t, will be in the standby status.
- Once ZooKeeper finds the Canal-server who created the Ephemeral Node breaks down, it will notify other Canal servers to repeat step 1, thus there will be another Canal-server starts to run.
- The same as canal-server, only one canal-client will be allowed to run simultaneously. When the canal-client starts, it will ask the ZooKeeper which canal-server is running, then it will connects to the running canal-server.
Note: The life cycle of Ephemeral Node in ZooKeeper only binds to its client’s session. If ZooKeeper loses the session of a client, the corresponding Ephemeral Node will be deleted automatically.
References
[1] Alibaba’s Canal official document: https://github.com/alibaba/canal
