
Java Thread Pool Executor
In Java, threads are mapped to system-level threads which are operating system’s resources. If you create threads uncontrollably, you may run out of these resources quickly. The Thread Pool pattern helps to save resources in a multi-threaded application, and also to contain the parallelism in certain predefined limits. When you use a thread pool, you write your concurrent code in the form of parallel tasks and submit them for execution to an instance of a thread pool. This instance controls several re-used threads for executing these tasks.
The pattern allows you to control the number of threads the application is creating, their lifecycle, as well as to schedule tasks’ execution and keep incoming tasks in a queue.
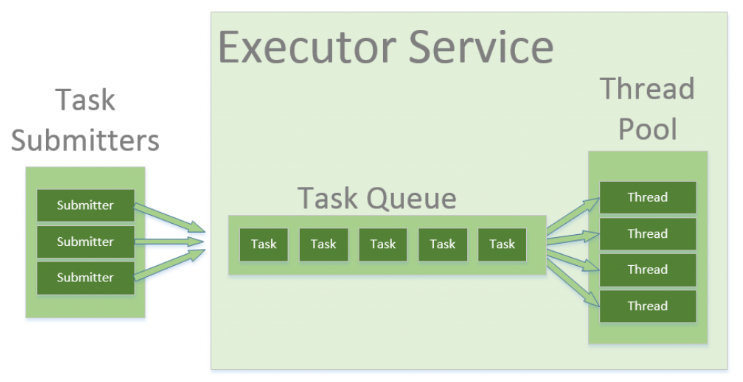
Executors, Executor and ExecutorService
The Executors helper class contains several methods for creation of pre-configured thread pool instances for you.
The Executor and ExecutorService interfaces are used to work with different thread pool implementations in Java. Usually, you should keep your code decoupled from the actual implementation of the thread pool and use these interfaces throughout your application.
The Executor interface has a single execute() method to submit Runnable instances for execution.
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Hello World"));
This example shows how you can use the Executors API to acquire an Executor instance backed by a single thread pool and an unbounded queue for executing tasks sequentially. The task is submitted as a lambda (a Java 8 feature) which is inferred to be Runnable.
The ExecutorService interface contains a large number of methods for controlling the progress of the tasks and managing the termination of the service. Using this interface, you can submit the tasks for execution and also control their execution using the returned Future instance.
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(() -> "Hello World");
// some operations
String result = future.get();
In this example, we create an ExecutorService, submit a task and then use the returned Future‘s get method to wait until the submitted task is finished and the value is returned.
The submit method is overloaded to take either Runnable or Callable both of which are functional interfaces and can be passed as lambdas (starting with Java 8).
Runnable‘s single method does not throw an exception and does not return value. Callable interface may be more convenient, as it allows to throw an exception and return a value. Finally, to let the compiler infer the Callable type, simply return a value from the lambda.
ThreadPoolExecutor
The ThreadPoolExecutor is an extensible thread pool implementation with lots of parameters and hooks for fine-tuning. The main configuration parameters that we’ll discuss here are: corePoolSize, maximumPoolSize, and keepAliveTime.
The pool consists of a fixed number of core threads that are kept inside all the time, and some excessive threads that may be spawned and then terminated when they are not needed anymore.
The corePoolSize parameter is the amount of core threads which will be instantiated and kept in the pool. If all core threads are busy and more tasks are submitted, then the pool is allowed to grow up to a maximumPoolSize. The keepAliveTime parameter is the interval of time for which the excessive threads (i.e. threads that are instantiated in excess of the corePoolSize) are allowed to exist in the idle state.
Examples:
-
newFixedThreadPool(): creates a ThreadPoolExecutor with equal corePoolSize and maximumPoolSize parameter values and a zero keepAliveTime. This means that the number of threads in this thread pool is always the same. If the amount of simultaneously running tasks is less or equal to two at all times, then they get executed right away. Otherwise some of these tasks may be put into a queue to wait for their turn.
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(2); executor.submit(() -> { Thread.sleep(1000); return null; }); -
newCachedThreadPool(): does not receive a number of threads at all. The corePoolSize is actually set to 0, and the maximumPoolSize is set to Integer.MAX_VALUE for this instance. The keepAliveTime is 60 seconds for this one. These parameter values mean that the cached thread pool may grow without bounds to accommodate any amount of submitted tasks. But when the threads are not needed anymore, they will be disposed of after 60 seconds of inactivity. A typical use case is when you have a lot of short-living tasks in your application.
The queue size in the example below will always be zero because internally a SynchronousQueue instance is used. In a SynchronousQueue, pairs of insert and remove operations always occur simultaneously, so the queue never actually contains anything.
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newCachedThreadPool(); executor.submit(() -> { Thread.sleep(1000); return null; }); -
newSingleThreadExecutor(): creates another typical form of ThreadPoolExecutor containing a single thread. The single thread executor is ideal for creating an event loop. The corePoolSize and maximumPoolSize parameters are equal to 1, and the keepAliveTime is zero.
AtomicInteger counter = new AtomicInteger(); ExecutorService executor = Executors.newSingleThreadExecutor(); executor.submit(() -> { counter.set(1); }); executor.submit(() -> { counter.compareAndSet(1, 2); });Tasks in the above example will be executed sequentially, so the flag value will be 2 after task’s completion.
Additionally, this ThreadPoolExecutor is decorated with an immutable wrapper, so it cannot be reconfigured after creation. Note that also this is the reason we cannot cast it to a ThreadPoolExecutor.
ScheduledThreadPoolExecutor
The ScheduledThreadPoolExecutor extends the ThreadPoolExecutor class and also implements the ScheduledExecutorService interface with several additional methods:
- schedule() method allows to execute a task once after a specified delay;
- scheduleAtFixedRate() method allows to execute a task after a specified initial delay and then execute it repeatedly with a certain period; the period argument is the time measured between the starting times of the tasks, so the execution rate is fixed;
- scheduleWithFixedDelay() method is similar to scheduleAtFixedRate in that it repeatedly executes the given task, but the specified delay is measured between the end of the previous task and the start of the next;
The Executors.newScheduledThreadPool() method is typically used to create a ScheduledThreadPoolExecutor with a given corePoolSize, unbounded maximumPoolSize and zero keepAliveTime.
Here’s how to schedule a task for execution in 500 milliseconds:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
executor.schedule(() -> {
System.out.println("Hello World");
}, 500, TimeUnit.MILLISECONDS);
The following code shows how to execute a task after 500 milliseconds delay and then repeat it every 100 milliseconds.
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
ScheduledFuture<?> future = executor.scheduleAtFixedRate(() -> {
System.out.println("Hello World");
}, 500, 100, TimeUnit.MILLISECONDS);
ForkJoinPool
ForkJoinPool is the central part of the fork/join framework introduced in Java 7. It solves a common problem of spawning multiple tasks in recursive algorithms. Using a simple ThreadPoolExecutor, you will run out of threads quickly, as every task or subtask requires its own thread to run.
In a fork/join framework, any task can spawn (fork) a number of subtasks and wait for their completion using the join method. The benefit of the fork/join framework is that it does not create a new thread for each task or subtask, implementing the Work Stealing algorithm instead. Simply put – free threads try to “steal” work from deques of busy threads.
Creating a RecursiveTask:
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
private int compute(int small) {
final int[] results = { 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 };
return results[small];
}
public Integer compute() {
if (n <= 10) {
return compute(n);
}
Fibonacci f1 = new Fibonacci(n - 1);
Fibonacci f2 = new Fibonacci(n - 2);
f1.fork();
f2.fork();
return f1.join() + f2.join(); // blocked until each subtask is finished
}
}
Then submit this task to ForkJoinPool:
@Test
public void testFibonacci() throws InterruptedException, ExecutionException {
ForkJoinTask<Integer> fjt = new Fibonacci(45);
ForkJoinPool fjpool = new ForkJoinPool();
Future<Integer> result = fjpool.submit(fjt);
// do something
System.out.println(result.get());
}
References
[1] Java Concurrency Interview Questions: http://www.baeldung.com/java-concurrency-interview-questions
[2] Class ThreadPoolExecutor: https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ThreadPoolExecutor.html
[3] Introduction to Thread Pools in Java: http://www.baeldung.com/thread-pool-java-and-guava
