
Maps In Java
Map is a data structure and it is mainly used for fast data lookups or searching. The Map interface in java is one of the four top level interfaces of Java Collection Framework along with List, Set and Queue interfaces. But, unlike others, it doesn’t inherit from Collection interface. Instead it starts its own interface hierarchy for maintaining the key-value associations. Map is an object of key-value pairs where each key is associated with a value. HashMap, LinkedHashMap, ConcurrentHashMap and TreeMap are four popular implementations of Map interface. In this article, we will discuss about the hierarchy, property and internal mechanisms of Map in Java.
Hierarchy of Maps
The Map interface doesn’t inherit from Collection interface, it starts its own hierarchy for maintaining the key-value associations. HashMap, LinkedHashMap, ConcurrentHashMap and TreeMap are four popular implementations of Map interface.
The picture below shows the class hierarchy structures of Map interface:
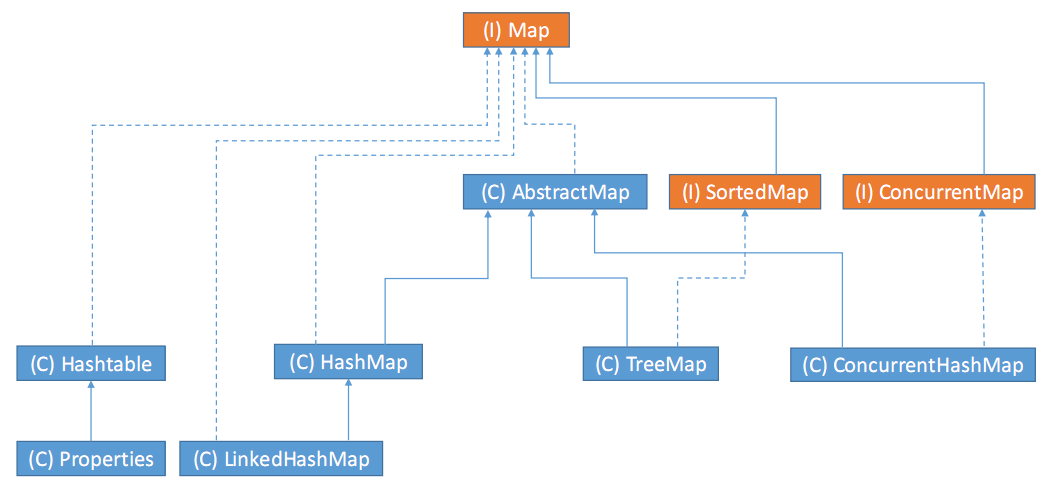
Note:
- (C) means class (blue), whereas (I) means interface (orange).
- The solid line means “extends”, whereas the dashed line means “implements”.
How HashMap Works Internally
If your application demands fast insertion and retrieval, then HashMap is the ultimate choice. HashMap is the most used data structure in java because it gives almost constant time performance of O(1) for put and get operations irrespective of how big is the data. As you already know, HashMap stores the data in the form of key-value pairs. In this section, we will see how HashMap works internally in java and how it stores the elements to give O(1) performance for put and get operations.
Internal Structure
HashMap stores the data in the form of key-value pairs. Each key-value pair is stored in an object of Entry<K, V> class. Entry<K, V> class is the static inner class of HashMap which is defined like below.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
//Some methods are defined here
}
As you can see, this inner class has four fields: key, value, next and hash.
- key : It stores the key of an element and it is final.
- value : It holds the value of an element.
- next : It holds the pointer to next key-value pair. This attribute makes the key-value pairs stored as a linked list.
- hash : It holds the hashcode of the key.
These Entry objects are stored in an array called table[]. This array is initially of size 16. It is defined like below:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table;
The picture below best summarizes the whole HashMap structure:
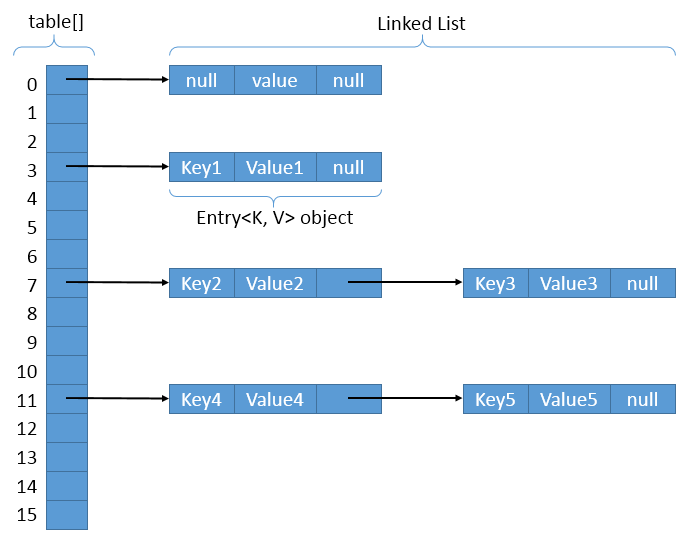
Internally HashMap uses an array of Entry<K, V> class called table[] to store the key-value pairs.
But how HashMap allocates slot in table[] array to each of its key-value pair is very interesting. It doesn’t inserts the objects as you put them into an array i.e. first element at index 0, second element at index 1 and so on. Instead it uses the hash code of the key to decide the index for a particular key-value pair. It is called Hashing.
What Is Hashing?
The whole HashMap data structure is based on the principle of Hashing. Hashing is nothing but the function or algorithm or method which when applied on any object/variable returns an unique integer value representing that object/variable. This unique integer value is called hash code. Hash function or simply hash said to be the best if it returns the same hash code each time it is called on the same object. Two objects can have same hash code.
HashMap has its own hash function to calculate the hash code of the key. Whenever you insert new key-value pair using put() method, HashMap blindly doesn’t allocate slot in the table[] array. Instead it calls hash() function on the key.
After calculating the hash code of the key, it calls indexFor() method by passing the hash code of the key and length of the table[] array. This method returns the index in the table[] array for that particular key-value pair.
How put() method works?
Below is the code implementation of put() method in the HashMap class.
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
Let’s see how this code works step by step:
- First checks whether the key is null or not. If the key is null, putForNullKey() method is called. table[0] is always reserved for null key. Because, hash code of null is 0.
- If the key is not null, then it calculates the hash code of the key by calling hash()method.
- Calls indexFor() method by passing the hash code calculated in step 2 and length of the table[] array. This method returns index in table[] array for the specified key-value pair.
- After getting the index, it checks all keys present in the linked list at that index ( or bucket). If the key is already present in the linked list, it replaces the old value with new value.
- If the key is not present in the linked list, it appends the specified key-value pair at the end of the linked list.
How get() method works?
Let’s see how get() method has implemented.
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K , V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
The steps are:
- First checks whether specified key is null or not. If the key is null, it calls getForNullKey() method.
- If the key is not null, hash code of the specified key is calculated.
- indexFor() method is used to find out the index of the specified key in the table[] array.
- After getting index, it will iterate though linked list at that position and checks for the key using equals() method. If the key is found, it returns the value associated with it. otherwise returns null.
Capacity, Load Factor and Rehashing
Capacity is just the number of buckets in the table[] array, it is set to 16 initially. The capacity of the HashMap is doubled each time it reaches the threshold. i.e. the capacity is increased to 32, 64, 128 when the threshold is reached. Load Factor is the measure which decides when to increase the capacity of the HashMap. The default load factor is 0.75.
When the number of elements in the map goes beyond Capacity * Load Factor, the elements in the original table[] array will be placed into a new table[] array, which has the double capacity of the original one. When this happens, the new index at which the value has to be put changes. Rehashing is a process where new HashMap object with new capacity is created and all old elements (key-value pairs) are placed into new object after recalculating their hash code.
While rehashing, the linked list for each bucket gets reversed in order. This happens because HashMap doesn’t append the new element at the tail instead it appends the new element at the head. So when rehashing occurs, it reads each element and inserts it in the new bucket at the head and then keeps on adding next elements from the old map at the head of the new map resulting in reversal of linked list. If there are multiple threads handling the same hash map it could result in infinite loop. This is called Race Condition.
HashMap vs. Hashtable
HashMap and Hashtable have some similarities in common:
- Both store the data in the form of key-value pairs.
- Both use Hashing technique to store the key-value pairs.
- Both implement Map interface.
- Both doesn’t maintain any order for elements.
- Both give constant time performance for insertion and retrieval operations.
But there are also many differences between them. The main differences can be summarized as below:
| differences | HashMap | Hashtable |
|---|---|---|
| thread safe | HashMap is not synchronized and therefore it is not thread safe. | HashTable is internally synchronized and therefore it is thread safe. |
| null key | HashMap allows maximum one null key and any number of null values. | HashTable doesn’t allow null keys and null values. |
| fail-fast vs. fail-safe | Iterators returned by the HashMap are fail-fast in nature. | Numeration returned by the HashTable are fail-safe in nature. |
| extends | HashMap extends AbstractMap class. | HashTable extends Dictionary class. |
| returns | HashMap returns only iterators to traverse. | HashTable returns both Iterator as well as Enumeration for traversal. |
| performance | HashMap is fast. | HashTable is slow. |
| legacy class | HashMap is not a legacy class. | HashTable is a legacy class. |
| when to use | HashMap is preferred in single threaded applications. If you want to use HashMap in multi threaded application, wrap it using Collections.synchronizedMap() method. | Although HashTable is there to use in multi threaded applications, nowadays it is not at all preferred. Because, ConcurrentHashMap is a better option than HashTable. |
ConcurrentHashMap
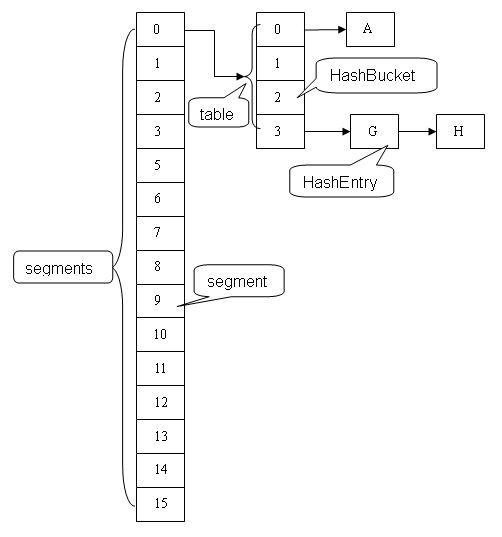
Collections.synchornizedMap(HashMap) will return a collection which is almost equivalent to Hashtable, where every modification operation on Map is locked on Map object. While in case of ConcurrentHashMap, thread-safety is achieved by dividing whole Map into different partitions (segments) based upon concurrency level and only locking particular partition instead of locking the whole Map.
The picture below best describes how the concurrency and thread-safety are achieved by segment lock.
TreeMap
The TreeMap class implements the NavigableMap interface and extends AbstractMap class by using a Red-Black Tree. A TreeMap provides an efficient means of storing key-value pairs in sorted order, and allows rapid retrieval. Unlike a hash map, a tree map guarantees that its elements will be sorted in an ascending key order.
Here’s the example of how to use it:
TreeMap treeMap = new TreeMap();
treeMap.put("Z", 1.1);
treeMap.put("D", 1.2);
treeMap.put("A", 1.3);
treeMap.put("F", 1.4);
for (Map.Entry entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
// output will be:
// A 1.3
// D 1.2
// F 1.4
// Z 1.1
As we can see, the elements in a TreeMap are sorted by the key in an ascending order.
TreeMap contains only unique elements, it cannot have null key but can have multiple null values.
LinkedHashMap
LinkedHashMap is same as HashMap instead maintains insertion order.
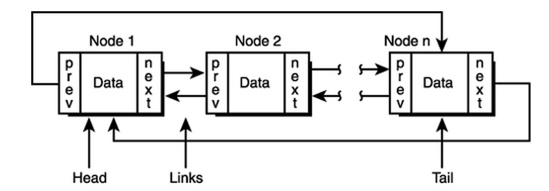
It maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order).
References
[1] How HashMap Works Internally In Java: http://javaconceptoftheday.com/how-hashmap-works-internally-in-java
[2] What is Load factor and Rehashing in HashMap: http://javabypatel.blogspot.com/2015/10/what-is-load-factor-and-rehashing-in-hashmap.html
[3] Rehashing Process in HashMap or Hashtable: https://stackoverflow.com/questions/10655239/rehashing-process-in-hashmap-or-hashtable
[4] How ConcurrentHashMap Works Internally In Java: https://dzone.com/articles/how-concurrenthashmap-works-internally-in-java
[5] 探索ConcurrentHashMap高并发性的实现机制: https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/index.html
[6] Difference between HashMap, LinkedHashMap and TreeMap: https://stackoverflow.com/questions/2889777/difference-between-hashmap-linkedhashmap-and-treemap
